数据结构与对象
简单动态字符串SDS
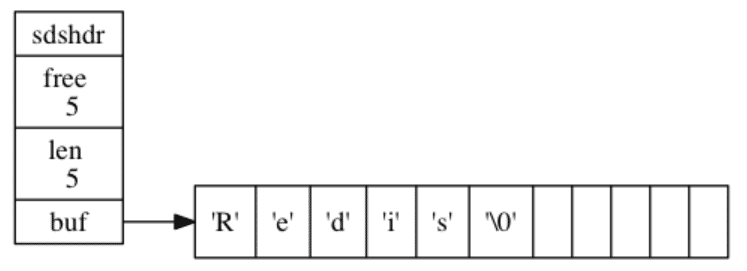
结构:
1 | struct sdshdr { |
字符串以空字符’\0’结尾,原因是可以重用一部分C字符串函数库里面的函数。例如执行
1 | printf("%s",s->buf); |
可以打印SDS保存的字符串值“Redis”,而无须为SDS编写专门的打印函数。
C字符串的缺陷:
- 如果程序执行的是增长字符串的操作, 比如拼接操作(append), 那么在执行这个操作之前, 程序需要先通过内存重分配来扩展底层数组的空间大小 —— 如果忘了这一步就会产生缓冲区溢出
- 如果程序执行的是缩短字符串的操作, 比如截断操作(trim), 那么在执行这个操作之后, 程序需要通过内存重分配来释放字符串不再使用的那部分空间 —— 如果忘了这一步就会产生内存泄漏
SDS比C字符串更适用于Redis的原因:
- 常数复杂度获取字符串长度
- C获取字符串长度需要从头到尾进行遍历,而SDS执行STRLEN命令的复杂度仅为O(1)
- 杜绝缓冲区溢出
- C中进行字符串拼接时,如果没有分配足够的空间 ,可能造成缓冲区溢出,而SDS会自动扩容
空间分配与释放策略:
-
空间预分配
- 如果修改后SDS的长度小于1MB,那么程序分配和len属性同样大小的未使用空间,这时len的值将和free的值相同,如果len的值变为13字节,buf数组的长度变为13+13+1=27字节
- 如果修改后SDS的长度大于等于1MB,那么程序会分配1MB的未使用空间,如果len的值变为30MB,那么程序会分配1MB的未使用空间,buf数组的长度变为30MB+1MB+1byte
-
惰性空间释放
- 字符串删除时,不会立即回收空间,而是使用free属性将这些字节的数量记录起来,并等待将来使用
1
sdstrim(s,"XY"); //移除SDS字符串中的所有‘X'和’Y‘
执行sdstrim之前的SDS:
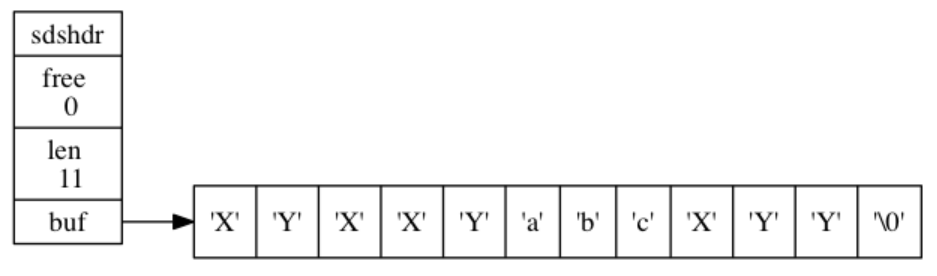
执行sdstrim之后的SDS:
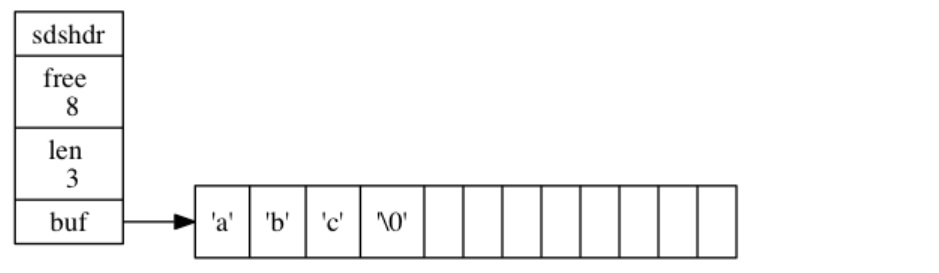
其它优点:
-
二进制安全
- SDS使用len属性的值而不是空字符来判断字符串是否结束
- C字符串除了字符串末尾,字符串里面不能包含空字符,C字符串只能保存文本数据,而不能保存图片。音频、视频这样的二进制数据
使用空字符分割单词的特殊数据格式:

例如这种含有空字符的数据格式,就不能使用C字符串来保存,因为C字符串所用的函数只会识别出其中的“Redis”,而忽略之后的“Cluster“。
总结:
| C字符串 | SDS |
|---|---|
| 获取字符串长度的复杂度为O(N) | 获取字符串长度的复杂度为O(1) |
| API是不安全的,可能会造成缓冲区溢出 | API是安全的,不会造成缓冲区溢出 |
| 修改字符串长度N次必然需要执行N次内存重分配 | 修改字符串长度N次最多需要执行N次内存重分配 |
| 只能保存文本数据 | 可以保存文本或者二进制数据 |
| 可以使用所有<string.h>库中的函数 | 可以使用一部分<string.h>库中的函数 |
哈希表

结构:
1 | typedef struct dictht { |
哈希表节点
1 | typedef struct dictEntry { |
字典
1 | typedef struct dict { |
一般情况下,字典只使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用。
普通状态下的字典 :
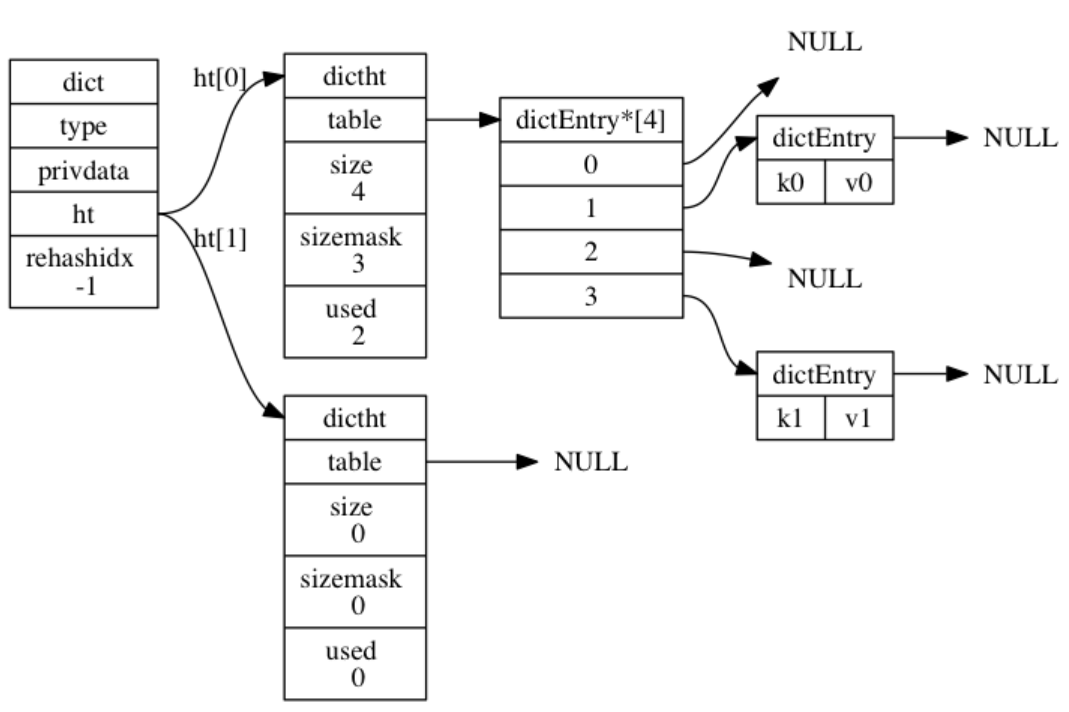
跳跃表

结构:
1 | typedef struct zskiplistNode { |
层
每次创建一个新跳跃表节点的时候,根据幂次定律(越大的数出现的概率越小)随机生成一个介于1和32之间的值作为level数组的大小,这个大小就是层的“高度”。
前进指针
用于从表头向表尾方向访问节点。
后退指针
每次只能后退至前一个节点
1 | typedef struct zskiplist { |
压缩列表
压缩列表是列表键和哈希键的底层实现之一。
压缩列表的结构:

- zlbytes:4字节,记录整个压缩列表占用的内存字节数
- zltail:4字节,记录压缩列表表尾节点距离压缩列表的起始地址有多少字节
- zllen:2字节,记录压缩列表包含的节点数量
- entryX:不定长,各个节点
- zlend:1字节,用于标记压缩列表的末端
每个节点的结构:

- previous_entry_length:记录压缩列表中前一个节点的长度
- 如果前一节点的长度小于254字节,那么previous_entry_length属性的长度为1字节
- 如果前一节点的长度大于等于254字节,那么previous_entry_length属性的长度为5字节,其中第一字节被设置为0xFE,后面的四个字节用于保存前一节点的长度
- encoding:记录了节点的content属性所保存数据的类型以及长度
- content:保存节点的值
参考
[1]redis设计与实现